Dans le domaine de l’assurance, le système “traditionnel” de traitement d’un sinistre ou d’une demande d’indemnisation fait appel à des processus encore très manuels, ce qui prend du temps et est sujet à erreurs, et par conséquent, entraîne des retards dans les paiements et une augmentation des frais de gestion. Il existe donc un potentiel d’optimisation et de baisse de coûts qui peut être réalisé grâce à l’IA Générative. Pour cela les LLMs doivent pouvoir raisonner sur les documents associés au processus de gestion. On entend ici le contrat mais pas que: tableaux de garantie, logigrammes de procédure, avenants, exemptions, etc. Cependant, dans cet exercice les LLMs sont confrontés à une limite qui est associée à leur fenêtre de contexte.
Qu’est ce qu’une fenêtre de contexte ?
La fenêtre de contexte est une méthode sophistiquée pour définir la quantité de mots qu’un grand modèle de langage peut traiter simultanément. Elle joue un rôle crucial dans le domaine du traitement de contenus en langage naturel. En ajustant la taille de la fenêtre, on peut déterminer la capacité du modèle à saisir le contexte d’une question, ce qui améliore sa capacité à fournir des réponses pertinentes et adaptées. Cette capacité à comprendre le contexte d’une requête est cruciale pour garantir des résultats précis de la part d’un LLM dans le contexte d’un processus métier faisant appel à des documents complexes de type contrat d’assurance.
Pourquoi est-ce important ?
Les fenêtres de contexte limitent la taille maximale de traitement du LLM, incluant souvent la réponse attendue, ce qui pose un défi majeur pour l’analyse de large sets de données comme des rapports ou des contrats de plusieurs dizaines de pages. En effet lorsque le contexte devient trop vaste, les performances du LLM diminuent significativement: plus le modèle traite de mots, moins les résultats sont satisfaisants car la fragmentation nécessaire du traitement, page par page, restreint la vue d’ensemble du modèle sur le corpus. Cela crée ainsi une limite sa capacité à comprendre la globalité des informations qui lui sont données. Pour pallier cette lacune, l’architecture RAG (Génération Augmentée de Récupération) pré-sélectionne les éléments pertinents du corpus, permettant ainsi au LLM de les traiter ensemble pour une compréhension globale du contexte. En résumé, l’approche RAG améliore l’analyse de données complexes en surmontant en partie la contrainte des fenêtres de contexte.
Limites du RAG
Cependant le RAG n’est pas une solution complète, surtout pour des situations professionnelles. Le RAG de base permet simplement de contourner la limite de contexte mais ne comporte aucune notion de métier, ce qui crée une nouvelle limite: pour lire et raisonner sur un document métier sophistiqué de plusieurs dizaines de pages comme un contrat d’assurance, il est nécessaire d’appliquer un mode de lecture correspondant au métier. C’est à dire d’interpréter les différentes parties du document en fonction de leur importance et de leur ordre dans la dite logique métier. Par exemple, les conditions générales d’un contrat peuvent être contredites par des clauses dans les conditions particulières. Autre exemple, il peut exister des avenants au contrat qui incluent des clauses nouvelles faisant appel à des documents tiers (un tableau de garantie, une procédure technique, etc.). Ainsi le RAG, pour produire des résultats conformes, doit être “piloté” par une chaine de commandes logicielles lui indiquant à quel moment du processus et sur quoi le LLM doit raisonner de manière à rester dans la logique métier.
LLM généralistes et le contrat d’assurance
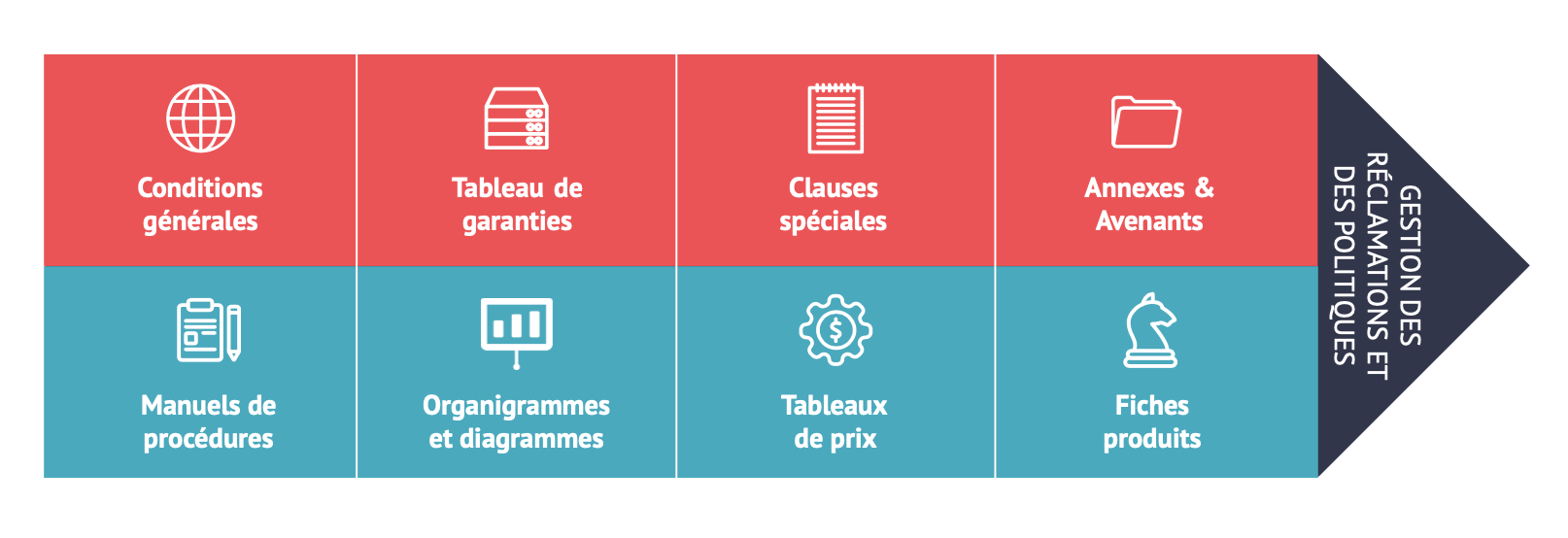
Un contrat assuranciel présente un niveau de complexité élevé compte tenu de ses composantes:
- Les parties contractantes : Tout d’abord, le contrat d’assurance identifie clairement les parties impliquées, à savoir l’assureur et l’assuré. Les coordonnées de chaque partie, y compris leur nom, adresse et autres informations pertinentes, sont généralement incluses.
- Les conditions générales : Les contrats d’assurance incluent des conditions générales qui s’appliquent à l’ensemble de la police.
- Les clauses : Différentes clauses définissent les conditions de la couverture. Elles définissent les risques couverts, les exclusions, les franchises, les limites de responsabilité, les primes, les modalités de paiement, les délais de réclamation, etc.
- La prime : Les modalités de paiement de la prime sont généralement spécifiées dans le contrat d’assurance. On y trouve la fréquence des paiements et les modes de paiement acceptés.
- Les garanties : Les garanties sont les engagements de l’assureur concernant les risques couverts par le contrat d’assurance. Elles définissent ce qui est assuré et dans quelles circonstances l’assureur versera une indemnisation à l’assuré en cas de sinistre.
- Les exclusions : Les exclusions sont les situations ou les événements pour lesquels l’assureur n’offre pas de couverture. Elles sont généralement énoncées de manière explicite dans le contrat d’assurance. Les exclusions peuvent varier en fonction du type d’assurance et des termes du contrat.
- Les avenants : Les avenants sont des modifications ou des ajouts au contrat d’assurance qui sont convenus entre l’assureur et l’assuré après la souscription initiale de la police. Ils peuvent être utilisés pour ajuster la couverture, modifier les termes ou ajouter des bénéficiaires, par exemple.
Les LLM généralistes ne peuvent pas raisonner sur les documents complexes associés à la vie du contrat et la gestion des sinistres/remboursements à cause de la limitation de leur fenêtre de contexte et de leur manque de spécialisation pour coller à la logique métier de l’assurance.
Comment Spellz résout-il le problème ?
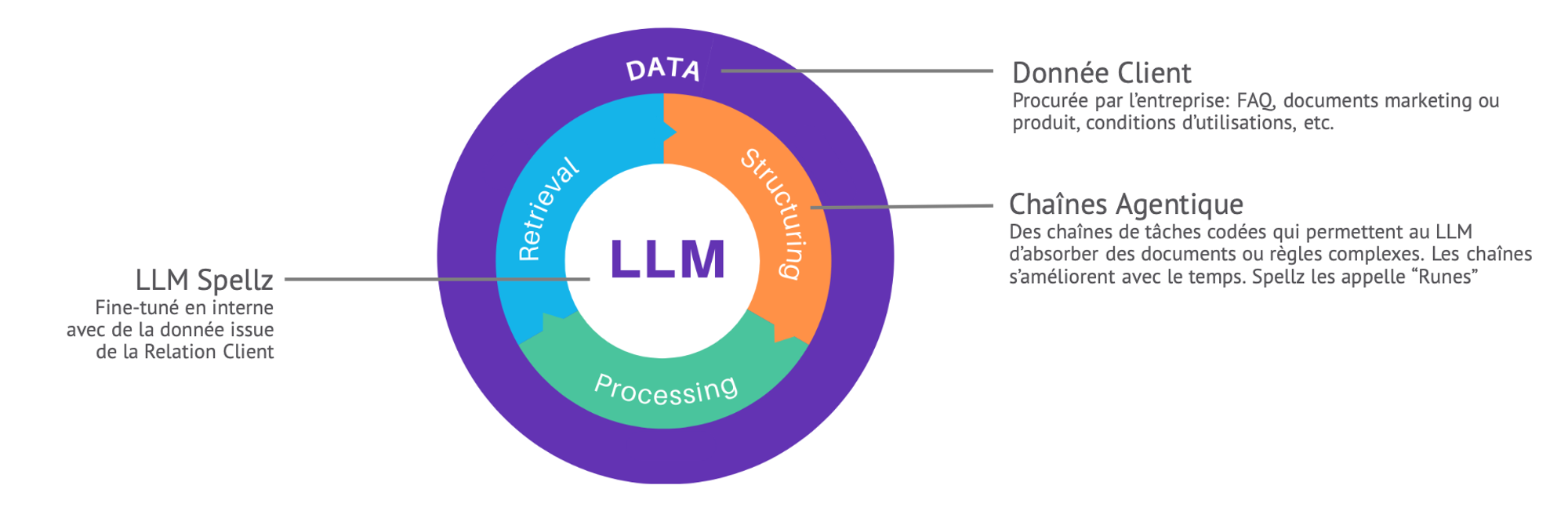
Pour s’affranchir des limitations de la fenêtre de contexte, Spellz opte pour une nouvelle approche de l’architecture RAG. Celle-ci permet de présélectionner les éléments pertinents de documents contractuels pour les présenter au LLM Spellz selon une chaîne d’étapes logicielles qui reproduit le processus métier du client (les étapes d’un parcours de logigramme par exemple) et aussi la façon dont un cerveau humain parcours ce processus. Le LLM n’est appelé à raisonner que quand cela est nécessaire, il est sollicité plusieurs fois pour une requête donnée, et il raisonne sur des éléments différents selon la position dans le processus. Cela se traduit par un comportement conforme à la logique métier et excellent rapport coût de calcul/performance.
Vous lancez bientôt un projet de développement d’IA générative ?
Parlons-nous en ⬇️