Définition LLM – MM
La grande majorité d’entre nous connait désormais les LLM (Large Language Models) depuis la sortie de ChatGPT en novembre 2022. Entrainés sur de vastes ensembles de données textuelles et utilisant des structures de réseaux neuronaux profonds, ces modèles sont conçus pour comprendre et produire du texte à partir de données textuelles. Autrement dit, ce sont des modèles unimodaux, Text-to-Text.
Un Multimodal Model (MM), en revanche sait traiter plusieurs types de données en entrée (input) comme en sortie (output). Ils peuvent ainsi comprendre et raisonner sur du texte, des images, photos ou visuels, de la vidéo, voire des actions. Et générer ces mêmes formats en réponse . Autrement dit, ces modèles, en en apportant des solutions aux limites des LLMs unimodaux (listées ci-dessous), offrent de nouvelles possibilités d’applications.
Limites des modèles unimodaux
- Biais unimodale : Les modèles unimodaux, en se basant sur un seul format d’information, peuvent être victimes de biais inscrits dans la composition de la modalité utilisée.
- Limitation de la compréhension du contexte : En traitant une seule modalité, ces modèles peuvent être limités dans leur capacité à comprendre pleinement le contexte ou manquer des informations cruciales disponibles dans d’autres formats.
- Erreurs : Les modèles unimodaux peuvent présenter des erreurs en raison des contraintes propres à la modalité unique sur laquelle ils reposent.
Fonctionnement des MM-LLMs
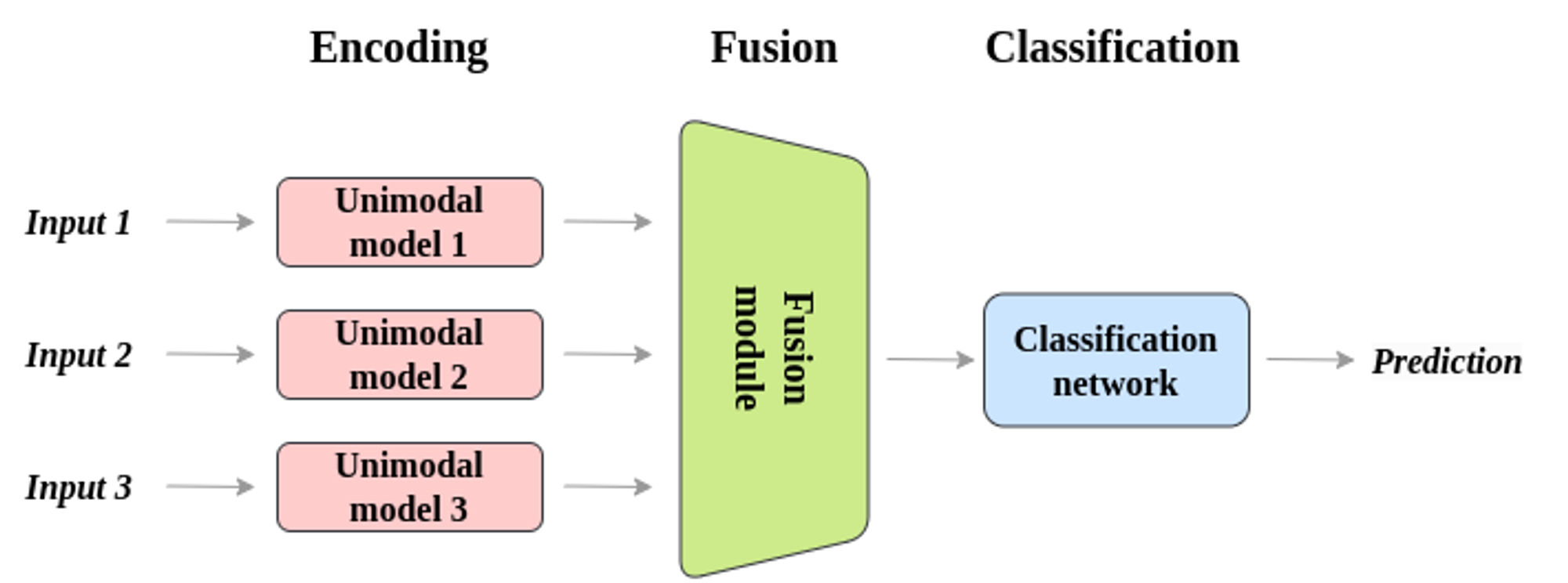
Le fonctionnement des modèles multimodaux est basé sur trois modules principaux :
- Module d’entrée : L’objectif des encodeurs unimodaux est d’extraire et de saisir les caractéristiques dans leur modalité spécifique. Par exemple, les données d’image sont traitées par un réseau de neurones convolutionnel (CNN) et les données textuelles par un réseau de neurones récurrents (RNN). Chaque réseau unimodal est entraîné indépendamment sur un jeu de données pertinent pour sa modalité.
- Module de fusion : Une fois l’extraction terminée, les caractéristiques des divers réseaux sont fusionnées à l’aide d’une méthode de fusion multimodale. Elle extrait les propriétés des réseaux qui traitent l’audio, les images et/ou le texte et les combine en une seule représentation partagée. La fusion multimodale vise principalement à regrouper des informations provenant de diverses sources afin de permettre à l’IA de saisir les relations et les liens entre elles.
- Module de sortie : Un classificateur multimodal est responsable de faire des prédictions ou des décisions basées sur la représentation des données fusionnées. Il s’agit d’une partie cruciale du modèle multimodal qui détermine le résultat final ou l’action que le système doit entreprendre. Après ces phases, un système d’IA multimodal peut saisir et exploiter des ensembles de données provenant de différentes sources.
Dans l’univers de la relation et de l’assurance, pour des raisons évoquées ci-dessus, les MM-LLMs offrent des possibilités élargies pour l’automatisation des processus métiers de la gestion et pour l’amélioration de l’expérience utilisateur.
Avantages pour l’automatisation dans l’assurance
Le MM-LLM présente des avantages significatifs pour le secteur de l’assurance car ces modèles permettent l’utilisation de données propriétaires que les assureurs ou courtiers sous-exploitent pour automatiser les processus métiers, notamment la gestion ou la vie du contrat.
- Schémas, logigrammes : l’IA lit et comprend un schéma détaillant l’articulation d’un processus pour l’automatiser ;
- Photo, visuels : l’IA analyse et détecte des éléments compris dans une photo ou un visuel et les intègre dans son raisonnement ;
- Vidéos : l’IA visionne une vidéo et en extrait des éléments cruciaux pour son raisonnement, comme les sons, les formes, les mouvements, les comportements, l’ordre des évènements et les relations spatiales.
- Données spatiales et tactiles
Cas d’usage Assurance
Assurance IARD
L’IA utilise des modèles multimodaux pour l’évaluation et le traitement en temps réel des images de sinistres, comme des dommages de véhicule ainsi que les descriptions écrites. Cette analyse permet d’évaluer de manière précise les dégâts, de vérifier rapidement la validité des réclamations et d’estimer les coûts de réparation. Cela accélère le traitement et la validation des réclamations d’assurance.
Une approche similaire est adoptée pour les dommages aux habitations, qui analyse les images des dégâts causés par des événements climatiques ou domestiques. Ces images sont associées à des descriptions afin d’évaluer les réparations nécessaires et anticiper les risques à venir en s’appuyant sur les données.
En ce qui concerne les objets de valeur, tels que les œuvres d’art, l’assurance évalue leur authenticité et leur valeur en associant l’analyse d’images avec les documents historiques, tout en surveillant leur état par des comparaisons d’images et de descriptions.
Assurance Santé
La lecture de documents visuels, tels que les diagrammes, et de diagnostics écrits est aussi optimisée pour analyser des diagrammes et des graphiques médicaux en parallèle des rapports de diagnostic écrits. Cette méthode permet une interprétation rapide et précise des diagnostics et des résultats médicaux. En intégrant cette méthode, les médecins peuvent prendre des décisions éclairées basées sur l’ensemble des tests effectués. L’automatisation des traitements et de la vérifications des documents médicaux réduit les erreurs humaines et accélère les processus, ce qui optimise le flux de travail.
Assurance de biens industriels
Dans le domaine de la robotique, les modèles multimodaux permettent aux robots de mieux comprendre et interagir avec leur environnement en intégrant plusieurs types de données simultanément. En combinant des données visuelles (images des caméras), auditives (sons captés par des microphones) et tactiles (données de capteurs de contact), les robots peuvent évoluer de manière plus efficace dans des environnements complexes. Ces données combinées leur permettent de reconnaître et de manipuler des objets avec une plus grande précision, ce qui leur permet d’ajuster leurs actions. De plus, cette approche renforce leur aptitude à interagir de manière plus naturelle avec les êtres humains, en comprenant mieux les intentions et les comportements à travers divers signaux sensoriels.
Conclusion
Les modèles multimodaux apportent des améliorations considérables dans divers aspects. Ils optimisent l’évaluation des risques en combinant diverses sources de données, pour une analyse plus complète et précise. Cette intégration renforce l’efficacité opérationnelle et améliore la précision globale. Ils contribuent à une efficacité opérationnelle accrue en intégrant et en traitant simultanément plusieurs types d’informations, ce qui optimise les processus et réduit les coûts. De plus, ils enrichissent l’expérience client en offrant des interactions plus naturelles et personnalisées.
- Amélioration de l’Évaluation des Risques
- Efficacité Opérationnelle
- Précision
- Amélioration de l’Expérience Client
- Innovation